
Creating a Yelling App in Kafka Streams
by
This blog post will quickly get you off the ground and show you how Kafka Streams works. We’re going to make a toy application that takes incoming messages and upper-cases the text of those messages, effectively yelling at anyone who reads the message. This application is called the “Yelling Application”.
Before diving into the code let’s take a look at the processing topology you’ll assemble for this “yelling” application. We’ll build a processing graph topology, where each node in the graph has a particular function.
NOTE: (Save 37% off Kafka Streams in Action with code streamkafka)
Figure 1 Graph or Topology of our Kafka Streams application, the
‘Yelling’ App
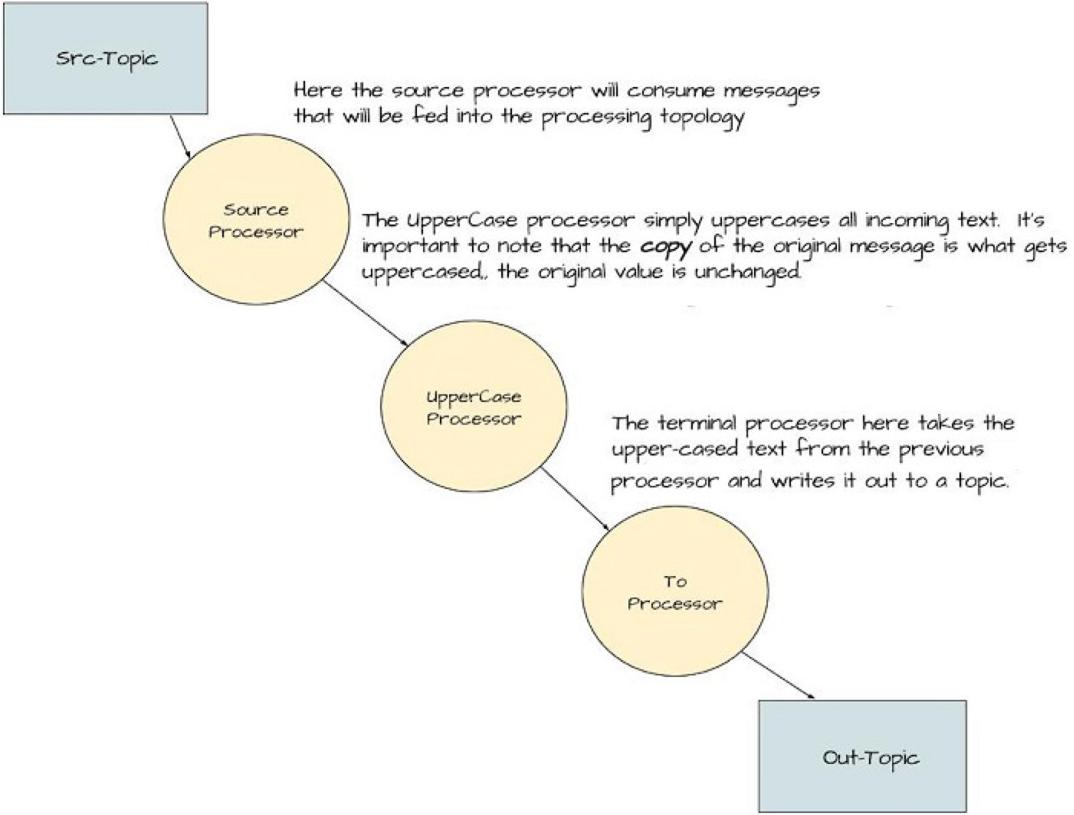
As you can see from the image, we’re building a simple processing graph. It’s simple enough to resemble a linked list of nodes more than the typical tree-like structure of a graph. But there’s enough here to give us strong clues as to what expect in the code. It requires a source node, a processor node that transforms incoming text to uppercase, and finally, a processor that writes results out to a topic. I’m going to show the whole application first; then I’ll walk through and explain each piece.
public class KafkaStreamsYellingApp {
public static void main(String[] args) {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "yelling_app_id");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
StreamsConfig streamingConfig = new StreamsConfig(props);
Serde<String> stringSerde = Serdes.String();
KStreamBuilder kStreamBuilder = new KStreamBuilder();
Stream<String,String> simpleFirstStream =kStreamBuilder.stream( stringSerde, stringSerde, "src-topic");
KStream<String, String> upperStream = simpleFirstStream.mapValues(String::toUpperCase);
upperStream.to(stringSerde, stringSerde, "out-topic");
KafkaStreams kafkaStreams = new KafkaStreams(kStreamBuilder,streamingConfig);
kafkaStreams.start();
}
}
Here are the main points of the program above
- Properties for configuring the Kafka Streams program (line 5).
- Creating the StreamsConfig with the given properties (line 8).
- Creating the Serdes used to serialize/deserialize keys and values (line 10).
- Creating the KStreamBuilder instance used to construct our processor topology (12).
- Creating the stream with a source topic to read from (Parent node in the graph) (line 13).
- A processor using a Java 8 method handle (first child node in the graph) (line 15).
- Writing the transformed output to another topic (last/terminal node in the graph) (line 16).
- Kicking off the Kafka Stream thread(s) (line 18).
This is a trivial example, but the code shown here is representative of what you’ll see in Kafka Streams programs. We will refer to this initial program points listed here throughout the blog.
With more advanced examples, the principal difference is the complexity of processor topology. With that in mind let’s take a walk through our first code sample presented here.
Configuration
Although Kafka Streams is highly configurable, with several properties you can adjust for your specific needs; our first example uses two configuration settings. Both of these are required because there are no default values provided. Attempting to start a Kafka Streams program without these two properties defined results in throwing a ConfigException.
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "yelling_app_id");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
-
StreamsConfig.APPLICATION_ID_CONFIG: This property identifies your Kafka Streams application and must be a unique value for the entire cluster. The application id config also serves as a default value for the client-id prefix and group-id parameters if you don’t set either value. The client-id prefix is the user-defined value used to identify clients connecting to Kafka uniquely. The group-id is used to manage the membership of a group of consumers all reading from the same topic and assures that many consumers can effectively read subscribed topics in the group.
-
StreamsConfig.BOOTSTRAP_SERVERS_CONFIG: The bootstrap servers configuration can be a single hostname:port setting or multiple values comma separated. The value of this setting should be apparent as it points the Kafka Streams application to the Kafka cluster.
Serde Creation
Serde<String> stringSerde = Serdes.String();
This line (from point number 3 of listing 1) is where you create the Serde instance required for serialization/deserialization of the key/value pair of every message, and store it in a variable for use later on. The Serde class provides default implementations for the following types:
-
Strings
-
Byte arrays
-
Long
-
Integer
-
Double
The Serde class is extremely useful as it’s used to contain the
serializer and deserializer, which eliminates the repetition for having
to specify four parameters (key serializer, value serializer, key
deserializer and value deserializer) every time you need to provide a
serde in a KStream method. In our next example, we’ll show how to create
your implementation to handle serialization/deserialization Serde of
more complex types.
Creating the Topology
Now let’s turn our attention to points 5, 6, and 7 from listing 1. It’s in these three sections of the code that we build up the processing topology or graph. We’ll present the graph with the relevant point highlighted to make it easier to follow how the code relates to the processing topology.
Figure 2 Creating the Source Node of the ‘Yelling’ App
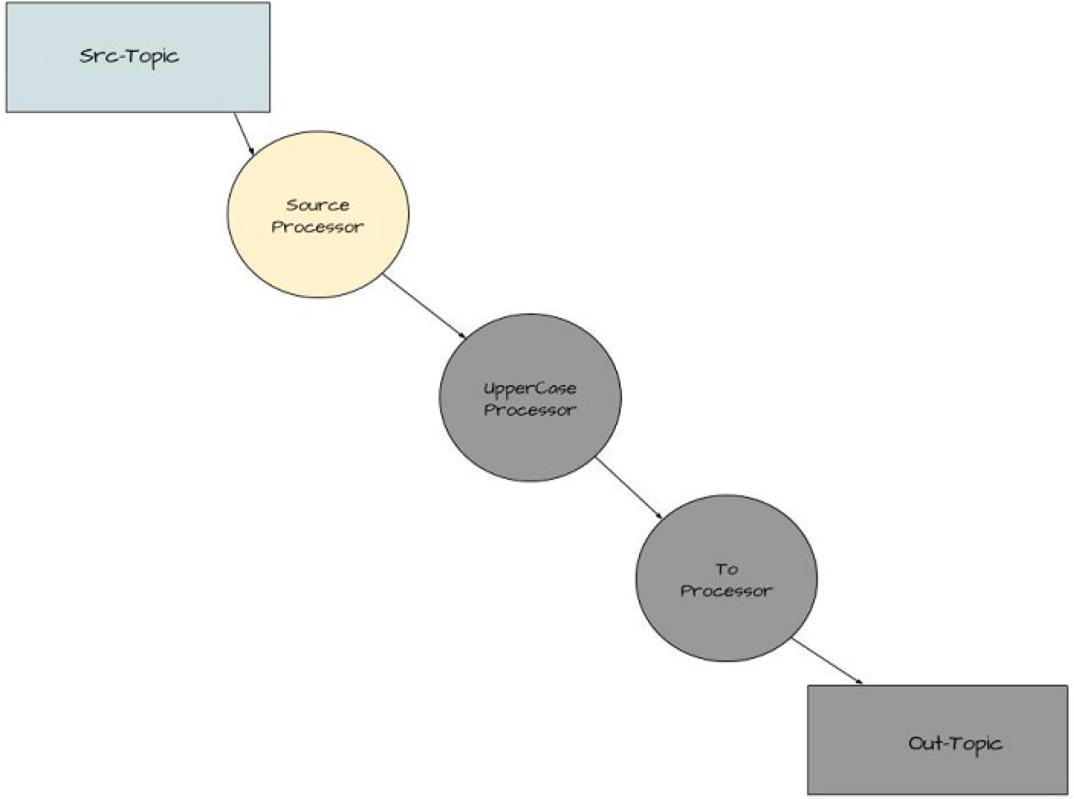
KStream<String,String> simpleFirstStream = kStreamBuilder.stream(stringSerde, stringSerde, "src-topic");
With this line of code (from point number 5), you’re creating the source or parent node of the graph. The source node of a topology consumes records from a given topic or topics.
In this case, it’s aptly named “src-topic” and the KStream instance
simpleFirstStream starts consuming messages written to this
topic.
Figure 3 Adding the UpperCase Processor to the ‘Yelling’ App
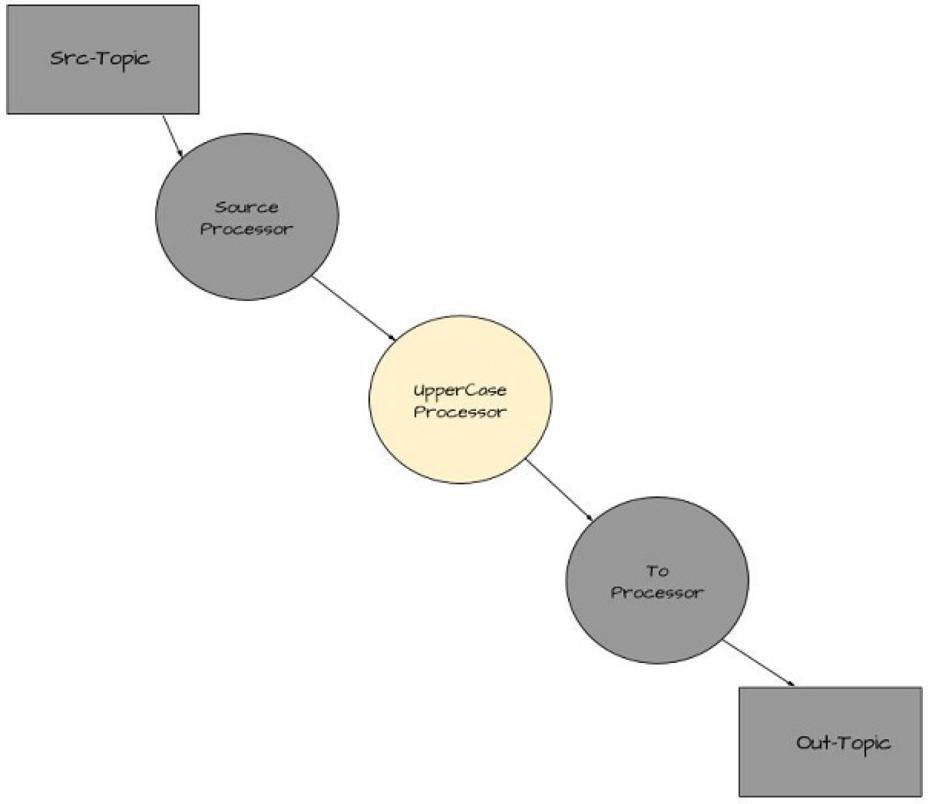
KStream<String, String> upperStream = simpleFirstStream.mapValues(String::toUpperCase);
With this line (point number 6) you’re creating another KStream instance
that’s a child node of the parent node. By calling the KStream.mapValues
function you’re creating a new processing node whose inputs are the
results of going through the mapValues call. It’s important to remember
that mapValues doesn’t modify the original values.
The upperStream instance receives transformed copies of the initial value from the simpleFirstStream.mapValues call. In this case, it’s upper-case text.
The mapValues method takes an instance of the ValueMapper<V, V1>
interface.
The interface defines only one method ValueMapper.apply, making it an ideal candidate for using a Java 8
lambda expression. We’ve done this with String::toUpperCase, which is a
method reference – an even shorter form of a Java 8 lambda expression.
NOTE: Although many Java 8 tutorials are available for lambda expressions and method references, good starting points are lamda expressions and method references respectively.
You could’ve used the form of (s) -> s.toUpperCase(), but because toUpperCase
is an instance method on the String class, we can use a method
reference. Using lambda expressions versus concrete implementations is a
pattern we’ll see over and over with the KStreams API. Most of the
methods expect types that are single method interfaces, and you can
easily use Java 8 lambdas.
Figure 4 Adding Processor for Writing ‘Yelling’ App Results
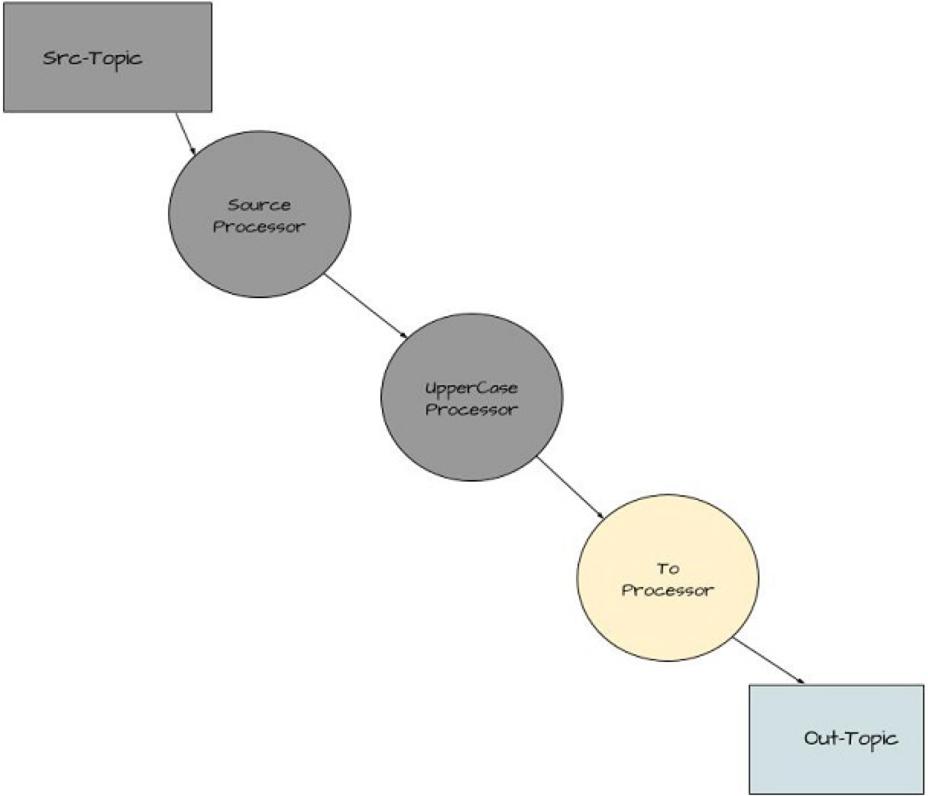 Figure 4 Adding Processor for Writing ‘Yelling’ App Results
Figure 4 Adding Processor for Writing ‘Yelling’ App Results
upperStream.to(stringSerde, stringSerde, "out-topic");
Here (point 7) we add the last processor in the graph. By calling the
method, you’re creating a terminal node in the topology – Kstream.to to
be more precise. You’re creating a sink node where the upperStream
processor writes the key-value pairs to a topic named “out-topic”.
Any KStream method that has a return type of void is a terminal node and it ends stream processing at that point, but it may not necessarily be a sink node. Again we see the pattern of providing the required serde instances needed for serialization/deserialization when reading from or writing to a Kafka topic.
NOTE: One note about serde usage in Kafka Streams. Several overloaded methods are in the KStream API where you don’t need to specify the key/value serdes. In those cases, the application uses the serializer/deserializer specified in the configuration instead.
In our example above we used three lines (steps 5, 6, and 7 from listing 1) to build the topology.
KStream<String,String> simpleFirstStream = kStreamBuilder.stream(stringSerde, stringSerde, "src-topic");
KStream<String, String> upperStream = simpleFirstStream.mapValues(String::toUpperCase);
upperStream.to(stringSerde, stringSerde, "out-topic");
Having each step on an individual line was used to demonstrate each stage of the building process clearly. All methods in the KStream API that don’t create terminal nodes return a new KStream instance. Returning a KStream object allows for using the “fluent interface” style of programming. To demonstrate this idea, here’s another way you could have constructed the yelling application topology:
kStreamBuilder.stream(stringSerde,stringSerde,"src-topic").mapValues(String::toUpperCase).to(stringSerde,stringSerde,"out-topic");
We shortened our program from three lines to one without losing any clarity or purpose.
Congratulations, you’ve constructed a Kafka Streams application! Let’s quickly review the steps taken, as it’s a general pattern seen in most Kafka Streams applications. Specifically, you took the following steps:
-
Created a StreamsConfig instance.
-
Then you created a Serde object.
-
You constructed a processing topology.
-
After putting all the pieces into place, you started the Kafka Streams program.
Aside from the general construction of a Kafka Streams application, a key takeaway here is to use lambda expressions whenever possible to make your programs more concise.
That’s all for this article. For more, download the free first chapter of Kafka Streams in Action and see this Slideshare presentation.
Subscribe via RSS